设计架构
Scheduler
k8s的有两步调度策略
- 预选策略(predicates):强制性规则,遍历所有Node,选择满足要求的Node列表。v1.7支持15种策略
- PodFitsResources:检查主机资源是否满足pod需求
- NoDiskConfilict:检查主机上的卷冲突
- MatchInterPodAffinity:检查pod和其他pod是否符合亲和性规则
- 优选策略(Priorities):在预选策略的基础上,给Node打分排序,选出最优者。v1.7支持10个策略,每项策略对应一个权重,每项策略的得分乘以权重得到总分
- ImageLocalityPriority:根据主机上是否已具备Pod运行的环境来打分,得分计算:不存在所需镜像,返回0分,存在镜像,镜像越大得分越高
- LeastRequestedPriority:计算Pods需要的CPU和内存在当前节点可用资源的百分比,具有最小百分比的节点就是最优,得分计算公式:cpu((capacity – sum(requested)) * 10 / capacity) + memory((capacity – sum(requested)) * 10 / capacity) / 2
Serviceaccount
一个角色拥有指定的资源权限(可以访问k8s里面的哪些资源,如pods、sercices等)和功能权限(CRUD),通过将RoleBinding将一个role绑定到某个serviceaccount上,即可让资源可通过serviceaccount来访问。关系图如下: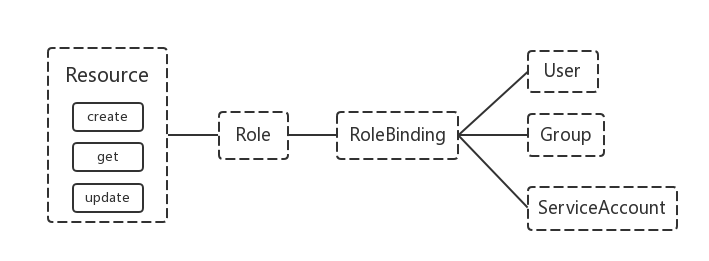
NodeStatus
在所有的 zones 都不健康(也即集群中没有健康 node)的极端情况下,node controller 将假设 master 的连接出了某些问题,它将停止所有删除动作直到一些连接恢复
containerd 架构
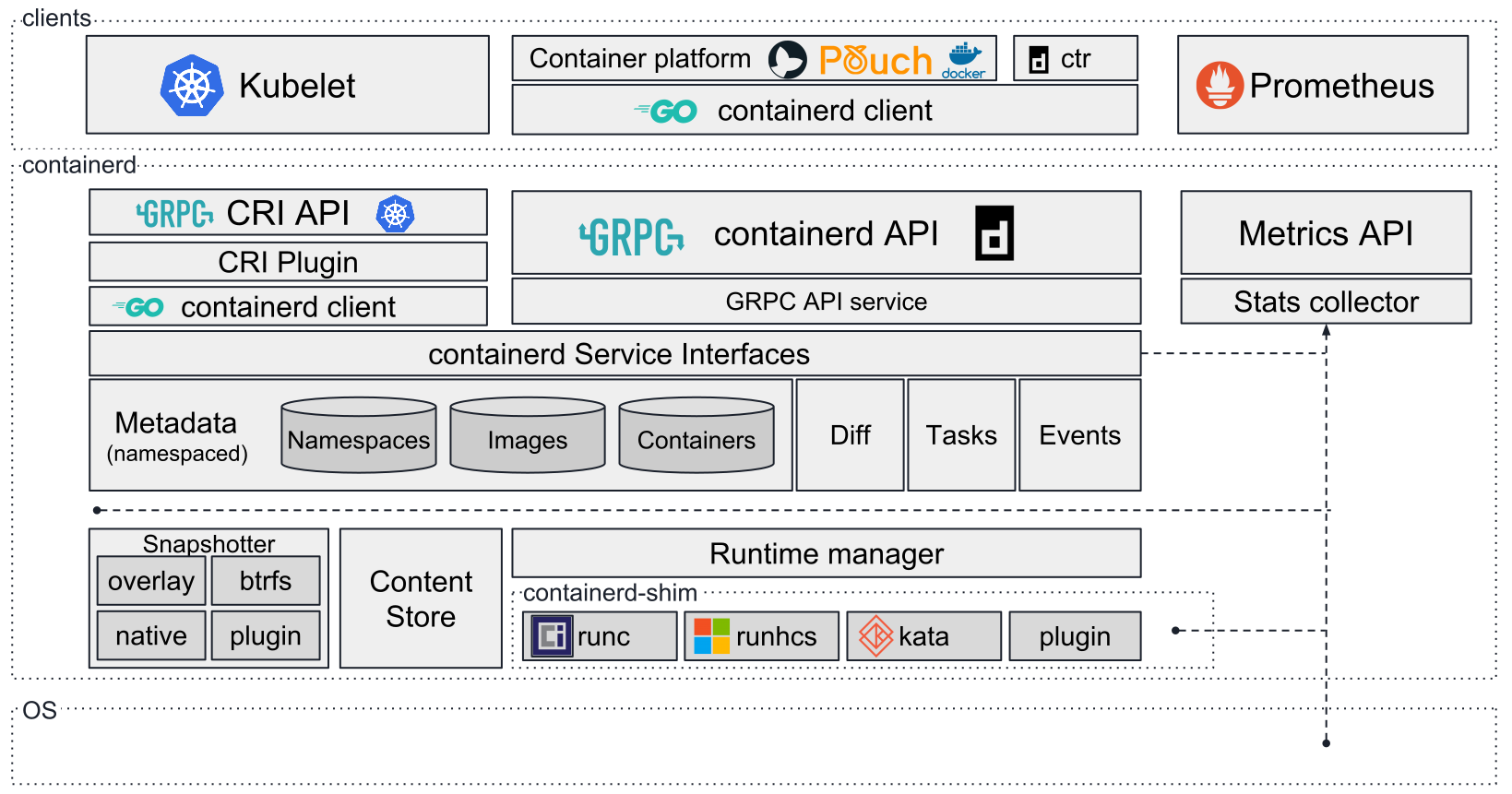
存储拓扑调度
在k8s中,存储是以PVC-StorageClass-PV的形式产生的,而存储的调度和pod的调度是两个并行的操作(前者由PV controller调度,后者由scheduler调度),所以两个并行独立的调度过程就很可能导致最终的存储访问不满足nodeAffinity的需求(比如pod和PV分别被调度到两个不同的region,而这两个region不能互相访问存储)。为了解决这个问题,k8s使用了存储拓扑调度,即将PV和PVC的binding操作和动态创建PV的操作做了delay,delay到pod调度结果出来之后,再去做这两个操作。使得最终选择的node既满足pod的计算资源需求,又满足pod的PV的nodeAffinity需求。需求对一些组件进行改动:
- PV controller需求支持延迟binding
- 动态生成PV的组件。pod调度结果出来之后,根据pod的拓扑信息动态创建PV
- kube-scheduler:在选择node的时候考虑计算资源的同时,需要考虑pod对存储的需求,即看选择的node是否能满足和PVC匹配的PV的nodeAffinity需求。
动态创建PV的拓扑限制需要保证两方面:一是动态创建出来的存储要能被这个可用区访问;二是调度器在选择node的时候,要落在这个可用区内。
k8s中支持使用Snapshot来进行存储快照,持久化卷