神经网络相关内容
神经网络
- 多层神经网络需要非线性映射。如果全连接层没有非线性部分,只有线性部分,那么计算之后,线性的多层神经网络其实可以转换成一层的神经网络。故加入非线性层,多层神经网络才有意义。
- 为防止使用sigmoid激活函数可能导致的梯度消失问题,激活函数一般取relu函数
- 每个神经元都是由输入图片(或者语音等)和该神经元所在层的前面所有层的连接矩阵(如卷积核)决定的,所以一个神经元其实就是一个变量,而连接矩阵是一组固定的权值,输入图片的不同会使该神经元输出不同的值。因此模型才能预测不同的图片所属的不同分类。我们保存的模型其实主要就是模型的连接矩阵,这也是神经网络训练过程中需要学习的
提高验证准确性的方法
- 增加数据集:Adding more data augmentations often reduces the gap between training and validation accuracy. Data augmentation could be reduced in epochs closer to the end.
- 初始学习率设置大一点:Start with a large learning rate and keep it large for a long time. For example, in CIFAR10, you could keep the learning rate at 0.1 for the first 200 epochs and then reduce it to 0.01.
- batch size不能太大:Do not use a batch size that is too large, especially batch size >> number of classes.
- batch_size增大,会使训练速度加快,不过太大会导致learning rate不好调,因为lr和batch size之间不是线性关系
- batch_size太小,模型训练的慢
Data Augmentation
人工增加训练集的大小,包括反射(image reflection)、平移(translation)、旋转(rotation)、加噪声等方法从已有的数据中创造一批新的数据
Batch Normalization
CNN网络在训练的过程中,前一层的参数变化影响着后面层的变化(因为前面层的输出是后面的输入),而且这种影响会随着网络深度的增加而不断放大。在CNN训练时,绝大多数都采用mini-batch使用随机梯度下降算法进行训练,那么随着输入数据的不断变化,以及网络中参数不断调整,网络的各层输入数据的分布则会不断变化,那么各层在训练的过程中就需要不断的改变以适应这种新的数据分布,从而造成网络训练困难,难以拟合的问题。
BatchNorm的目的是将每一层的输入数据进行归一化(normalization),使得每一层的数据分布是稳定的–均值0方差1,增加两个可学习的参数 β 和 γ ,对数据进行缩放和平移,从而达到加速训练的目的
momentum
用来加速训练过程的。引入momentum后,采用如下公式:
1 | v = mu * v - learning_rate * dw |
v初始为0,mu是一个超参数,一般设置为0.9。这样理解:如果上一次v和这一次的负梯度方向是相同的,则w下降的幅度会加大,从而使收敛的速度加快;反之,w下降的幅度会减小,收敛的速度减慢。
Softmax函数
即归一化指数函数,Softmax函数将向量等比例压缩到[0,1]之间,且保证所有元素之和为1。在多分类问题中用作输出层。
$$ softmax(i) = \frac{e^i}{\sum_{j}e^j} $$
向量里面的每个元素都可能取到,只是取到的概率由softmax函数求出的值给出。
在做反向传播的时候,也很方便,只需将softmax算出来的类别向量对应的真正结果的那一维减一就可以了。比如通过若干层的计算,最后得到的某个训练样本的向量的分数是[ 1, 5, 3 ],那softmax计算出来的概率就是$[\frac{e^1}{e^1 + e^3 + e^5},\frac{e^5}{e^1 + e^3 + e^5},\frac{e^3}{e^1 + e^3 + e^5}]=[ 0.015, 0.866, 0.117 ]$,如果这个样本正确的分类是第二个的话,那么计算出来的偏导就是$[ 0.015, 0.866 - 1, 0.117 ] = [ 0.015, -0.134, 0.117 ]$,然后根据这个偏导做反向传播,更新参数值。
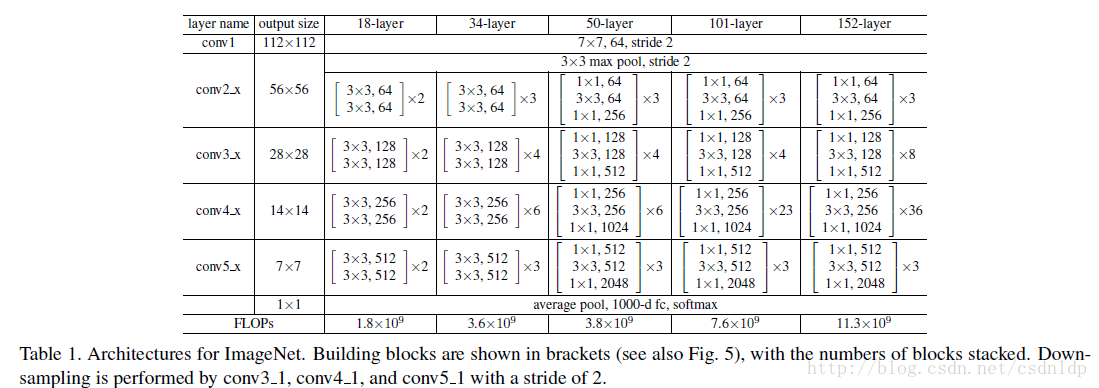
resnet模型
反向传播是一张图片处理完成之后就开始还是等待一个batch处理完之后开始?
答案是等待一个batch处理完之后开始。从Mxnet代码可以看出:module.forward_backward方法里就两句话:self.forward(batch) 和self.backward。
反向传播使用多少个loss?
一个batch处理完之后做backward,先拿到forward时产生的batch_size个loss,如果选择sgd来做梯度下降,那么sgd选择多少个loss做backward?答案是会将batch_size个loss平均之后做backward,因为这里使用的sgd是mini-batch sgd,即一个mini-batch完成前向处理后,将loss平均之后做backward,而不是只使用其中一个loss做backward。