NCCL 概念 NVIDIA Collective Communication Library是一个GPU拓扑感知的,提供了多GPU collective通信的库。
NCCL只能支持到8张GPU的深度学习训练(参见 )
开发者文档nccl2.3
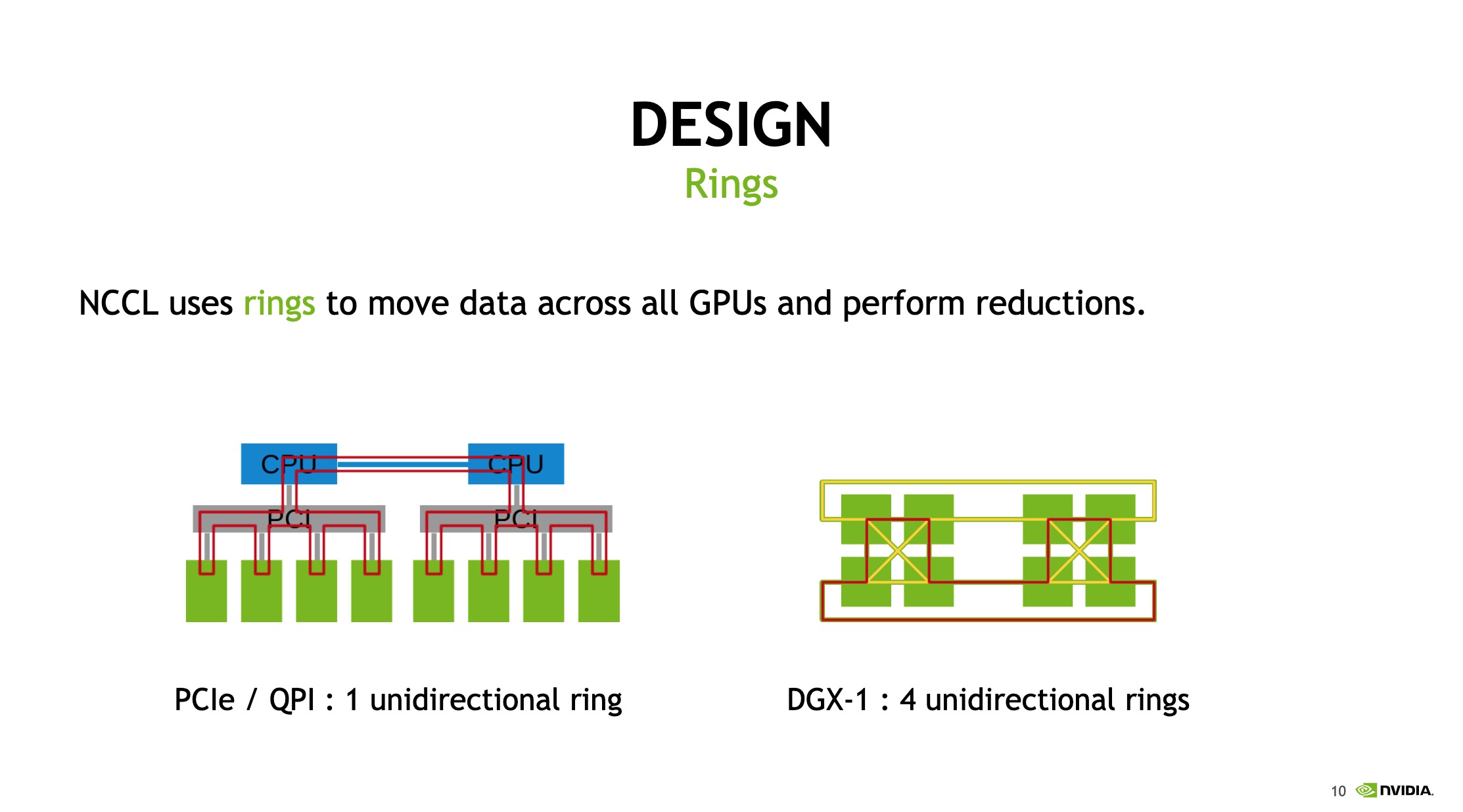
在nccl2.4介绍文档 中提到NCCL的All Reduce操作被用于百度ring-all-reduce和Horovod这两个使用ring的分布式训练框架中来获取GPU之间的full bandwidth。但同时提到ring的缺点是随着GPU数目的增长,延迟也成线性增加。为什么延迟会呈线性增加? ,很简单,因为每个GPU每次发送完一个chunk就必须等下一个chunk从另一张GPU发过来,整个过程(包括reduce scatter和all gather)总共需要发送2(n-1)次,则延时为2(n-1)的倍数。见NCCL collective示意图
性能测试 编译NVIDIA官方nccl-tests ,在8张Tesla V100 GPU机器上测试,GPU机器的拓扑如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 root@9a417caaf03b:~/nccl-tests GPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7 CPU Affinity GPU0 X NV1 NV1 NV2 SYS SYS NV2 SYS 0-95 GPU1 NV1 X NV2 NV1 SYS SYS SYS NV2 0-95 GPU2 NV1 NV2 X NV2 NV1 SYS SYS SYS 0-95 GPU3 NV2 NV1 NV2 X SYS NV1 SYS SYS 0-95 GPU4 SYS SYS NV1 SYS X NV2 NV1 NV2 0-95 GPU5 SYS SYS SYS NV1 NV2 X NV2 NV1 0-95 GPU6 NV2 SYS SYS SYS NV1 NV2 X NV1 0-95 GPU7 SYS NV2 SYS SYS NV2 NV1 NV1 X 0-95 Legend: X = Self SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI) NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU) PXB = Connection traversing multiple PCIe switches (without traversing the PCIe Host Bridge) PIX = Connection traversing a single PCIe switch NV
执行nccl-tests里面的all_reduce_perf性能测试,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 root@9a417caaf03b:~/nccl-tests 8 2 float sum 48.46 0.00 0.00 1e-07 48.17 0.00 0.00 1e-07 16 4 float sum 48.61 0.00 0.00 6e-08 49.16 0.00 0.00 6e-08 32 8 float sum 48.48 0.00 0.00 6e-08 48.14 0.00 0.00 6e-08 64 16 float sum 48.92 0.00 0.00 6e-08 48.50 0.00 0.00 6e-08 128 32 float sum 48.13 0.00 0.00 6e-08 48.25 0.00 0.00 6e-08 256 64 float sum 48.47 0.01 0.01 6e-08 48.50 0.01 0.01 6e-08 512 128 float sum 48.56 0.01 0.02 6e-08 48.29 0.01 0.02 6e-08 1024 256 float sum 48.88 0.02 0.04 2e-07 48.83 0.02 0.04 2e-07 2048 512 float sum 49.40 0.04 0.07 2e-07 49.15 0.04 0.07 2e-07 4096 1024 float sum 49.13 0.08 0.15 2e-07 48.97 0.08 0.15 2e-07 8192 2048 float sum 49.14 0.17 0.29 2e-07 49.25 0.17 0.29 2e-07 16384 4096 float sum 50.35 0.33 0.57 2e-07 49.77 0.33 0.58 2e-07 32768 8192 float sum 51.06 0.64 1.12 2e-07 50.78 0.65 1.13 2e-07 65536 16384 float sum 52.78 1.24 2.17 2e-07 52.64 1.24 2.18 2e-07 131072 32768 float sum 56.56 2.32 4.06 2e-07 55.63 2.36 4.12 2e-07 262144 65536 float sum 60.26 4.35 7.61 2e-07 59.48 4.41 7.71 2e-07 524288 131072 float sum 61.48 8.53 14.92 2e-07 61.34 8.55 14.96 2e-07 1048576 262144 float sum 89.27 11.75 20.56 2e-07 88.45 11.85 20.75 2e-07 2097152 524288 float sum 119.6 17.53 30.68 2e-07 116.7 17.97 31.45 2e-07 4194304 1048576 float sum 147.4 28.45 49.79 2e-07 145.1 28.91 50.59 2e-07 8388608 2097152 float sum 203.8 41.16 72.03 2e-07 204.0 41.12 71.97 2e-07 16777216 4194304 float sum 324.1 51.77 90.59 2e-07 325.7 51.51 90.14 2e-07 33554432 8388608 float sum 550.8 60.92 106.62 2e-07 553.3 60.64 106.12 2e-07 67108864 16777216 float sum 992.7 67.60 118.30 2e-07 995.0 67.45 118.04 2e-07 134217728 33554432 float sum 1818.8 73.80 129.14 2e-07 1821.9 73.67 128.92 2e-07
algbw = S/t,S表示数据量,t表示操作完S数据量所用时间。这里操作可以使all reduce、all gather等collective operation。以128MB数据测试结果为例:algbw = 134217728/(1818.8*10^(-6))/1000^3 = 73.80 GB/s。
busbw = algbw * 2(n-1)/n,n表示collective operation中节点的个数,在这里即为./build/all_reduce_perf -b 8 -e 128M -f 2 -g 8参数-g的值,即GPU的数目。
思考 ncclAllReduce是如何进行GPU间通信的? 按照ring的形式还是tree的形式?查看gtc 2017 nccl 2.0 report ,其中描述了nccl使用ring的形式在GPU之间交换数据,如下图:nccl的设计和实验
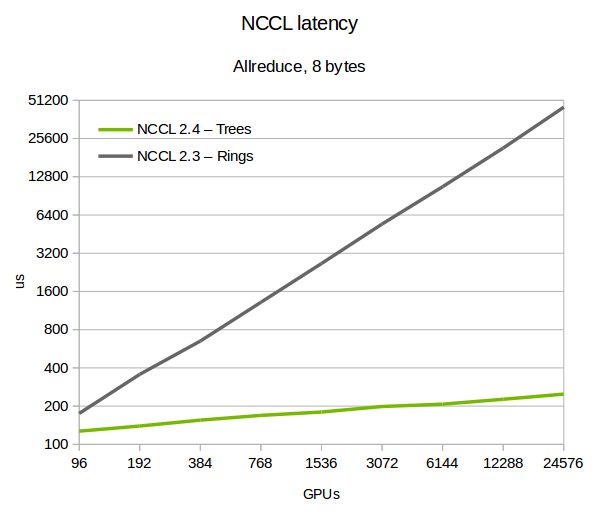
在nccl 2.4中引入了double binary trees,见nccl2.4介绍文档 ,从效果来看延迟改善了不少,如下图:
ncclAllReduce是如何构造一条带宽最大的环? nccl 2.4及以前版本中有一个环境变量NCCL_RINGS可以用来覆盖NCCL构造的GPU环,见NCCL_RINGS
nccl 2.5之后可以通过设置NCCL_ALGOTree,Ring,Collnet,猜测这是按照优先级排列的。